Introduction
Slumber is a terminal-based HTTP client, built for interacting with REST and other HTTP clients. It has two usage modes: Terminal User Interface (TUI) and Command Line Interface (CLI). The TUI is the most useful, and allows for interactively sending requests and viewing responses. The CLI is useful for sending quick requests and scripting.
The goal of Slumber is to be easy to use, configurable, and sharable. To that end, configuration is defined in a YAML file called the request collection. Both usage modes (TUI and CLI) share the same basic configuration, which is called the request collection.
Check out the Getting Started guide to try it out, or move onto Key Concepts to start learning in depth about Slumber.
Install
See installation instructions. Optionally, after installation you can enable shell completions.
Getting Started
Quick Start
Once you've installed Slumber, setup is easy.
1. Create a Slumber collection file
Slumber's core feature is that it's source-based. That means you write down your configuration in a file first, then run Slumber and it reads the file. This differs from other popular clients such as Postman and Insomnia, where you define your configuration in the app, and it saves it to a file for you. The goal of being source-based is to make it easy to save and share your configurations.
The easiest way to get started is to generate a new collection with the new subcommand:
slumber new
2. Run Slumber
slumber
This will start the TUI, and you'll see the example requests available. Use tab/shift+tab (or the shortcut keys shown in the pane headers) to navigate around. Select a recipe in the left pane, then hit Enter to send a request.
Going Further
Now that you have a collection, you'll want to customize it. Here's another example of a simple collection, showcasing multiple profiles:
# slumber.yml
profiles:
local:
data:
host: http://localhost:5000
production:
data:
host: https://myfishes.fish
requests:
create_fish: !request
method: POST
url: "{{host}}/fishes"
body: !json { "kind": "barracuda", "name": "Jimmy" }
list_fish: !request
method: GET
url: "{{host}}/fishes"
query:
- big=true
Note: the
!requesttag, which tells Slumber that this is a request recipe, not a folder. This is YAML's tag syntax, which is used commonly throughout Slumber to provide explicit configuration.
This request collection uses templates and profiles, allowing you to dynamically change the target host.
To learn more about the powerful features of Slumber you can use in your collections, keep reading with Key Concepts.
Key Concepts
There are a handful of key concepts you need to understand how to effectively configure and use Slumber. You can read about each one in detail on its linked API reference page.
Request Collection
The collection is the main form of configuration. It defines a set of request recipes, which enable Slumber to make requests to your API.
Request Recipe
A recipe defines which HTTP requests Slumber can make. A recipe generally corresponds to one endpoint on an API, although you can create as many recipes per endpoint as you'd like.
Template
Templates are Slumber's most powerful feature. They allow you to dynamically build URLs, query parameters, request bodies, etc. using predefined or dynamic values.
Profile
A profile is a set of static template values. A collection can contain a list of profiles, allowing you to quickly switch between different sets of values. This is useful for using different deployment environments, different sets of IDs, etc.
Terminal User Interface
The Terminal User Interface (TUI) is the primary use case for Slumber. It provides a long-lived, interactive interface for sending HTTP requests, akin to Insomnia or Postman. The difference of course is Slumber runs entirely in the terminal.
To start the TUI, simply run:
slumber
This will detect your request collection file according to the protocol. If you want to load a different file, you can use the --file parameter:
slumber --file my-slumber.yml
Auto-Reload
Once you start your Slumber, that session is tied to a single collection file. Whenever that file is modified, Slumber will automatically reload it and changes will immediately be reflected in the TUI. If auto-reload isn't working for some reason, you can manually reload the file with the r key.
Multiple Sessions
Slumber supports running multiple sessions at once, even on the same collection. Request history is stored in a thread-safe SQLite, so multiple sessions can safely interact simultaneously.
If you frequently run multiple sessions together and want to quickly switch between them, consider a configurable terminal manager like tmux or Zellij.
In-App Editing & File Viewing
Editing
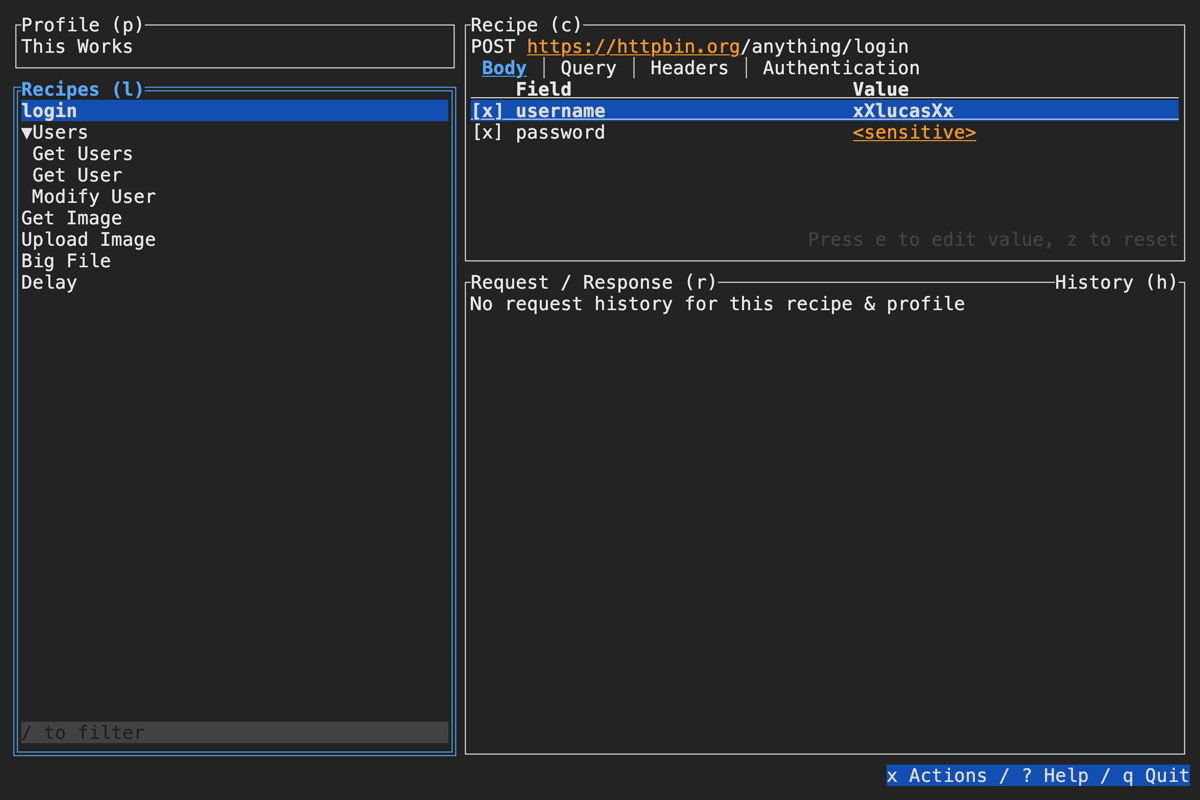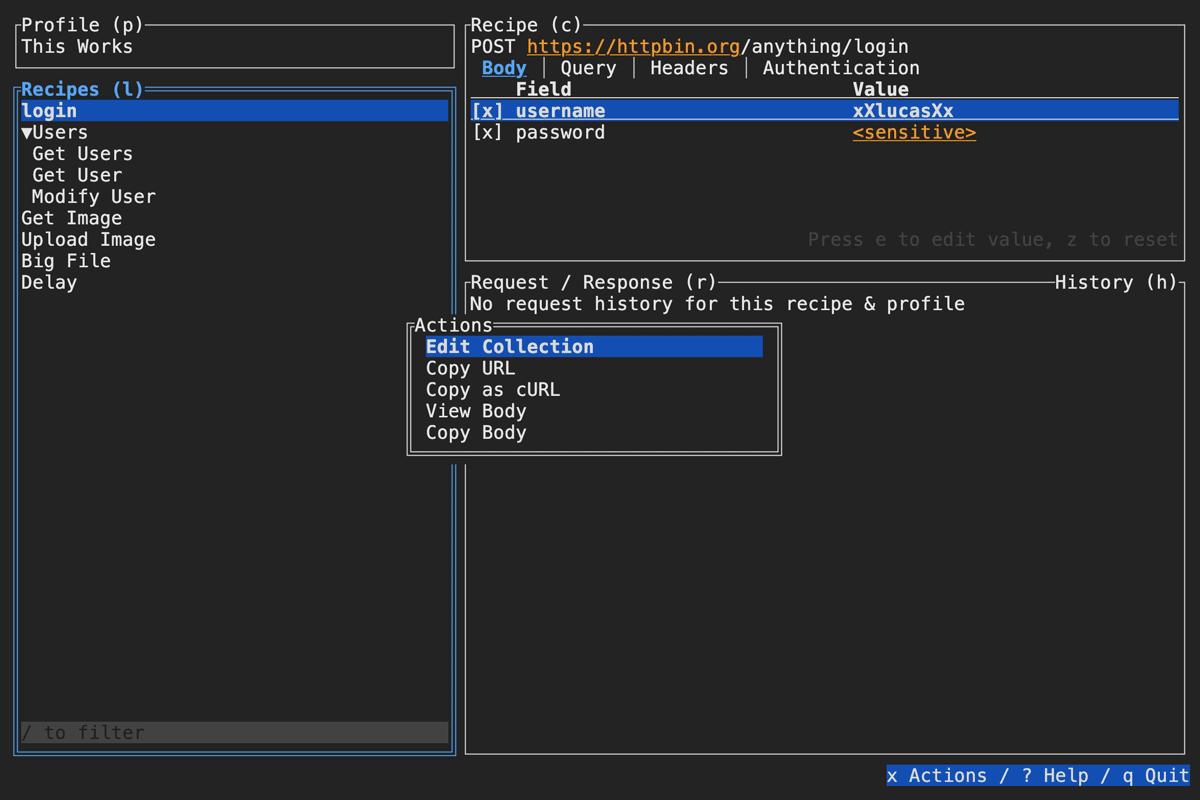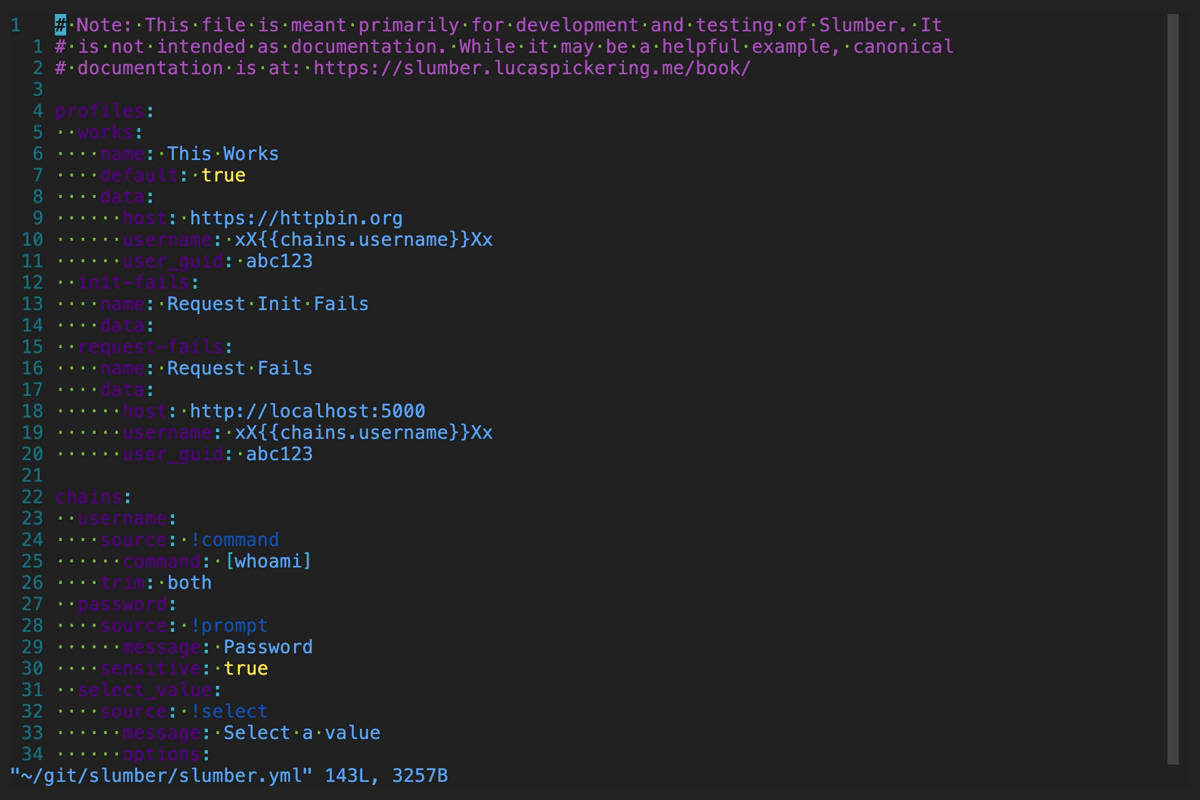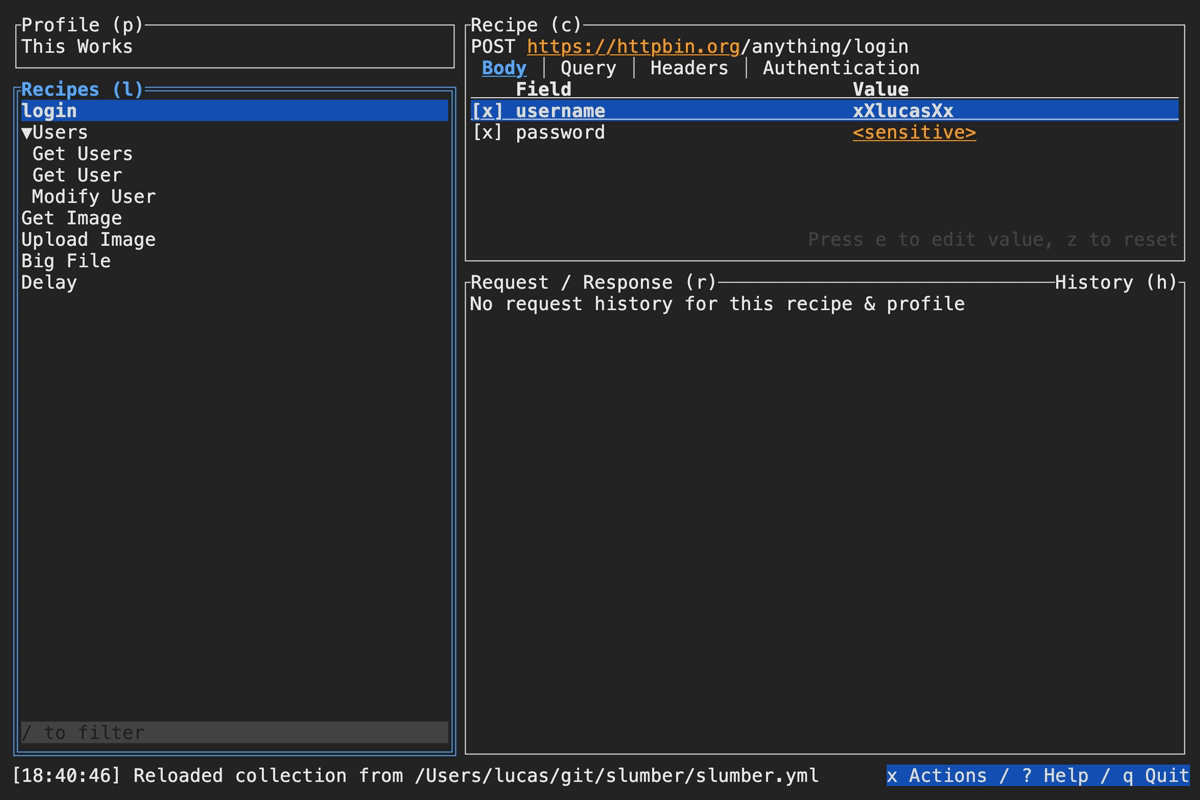
Slumber supports editing your collection file without leaving the app. To do so, open the actions menu (x by default), then select Edit Collection. Slumber will open an external editor to modify the file. To determine which editor to use, Slumber checks these places in the following order:
editorfield of the configuration fileVISUALenvironment variableEDITORenvironment variable- Default to
vim
The VISUAL and EDITOR environment variables are a common standard to define a user's preferred text editor. For example, it's what git uses by default to determine how to edit commit messages. If you want to use the same editor for all programs, you should set these. If you want to use a command specific to Slumber, set the editor config field.
Slumber supports passing additional arguments to the editor. For example, if you want to open VSCode and have wait for the file to be saved, you can configure your editor like so:
editor: code --wait
The command will be parsed like a shell command (although a shell is never actually invoked). For exact details on parsing behavior, see shell-words.
Paging
You can open request and response bodies in a separate file browser if you want additional features beyond what Slumber provides. To configure the command to use, set the PAGER environment variable or the pager configuration field:
pager: bat
Slumber will check these places in the following order for a command:
pagerfield of the configuration filePAGERenvironment variable- Default to
less(Unix) ormore(Windows)
The pager command uses the same format as the
editorfield. The command is parsed with shell-words, then a temporary file path is passed as the final argument.
To open a body in the pager, use the actions menu keybinding (x by default, see input bindings), and select View Body.
Some popular pagers:
Setting a content-specific pager
If you want to use a different pager for certain content types, such as using jless for JSON, you can pass a map of MIME type patterns to commands. For example:
pager:
json: jless
default: less
For more details on matching, see MIME Maps.
Data Filtering & Querying
When browsing an HTTP response in Slumber, you may want to filter, query, or otherwise transform the response to make it easier to view. Slumber supports this via embedded shell commands. The query box at the bottom of the response pane allows you to execute any shell command, which will be passed the response body via stdin and its output will be shown in the response pane. You can use grep, jq, sed, or any other text processing tool.
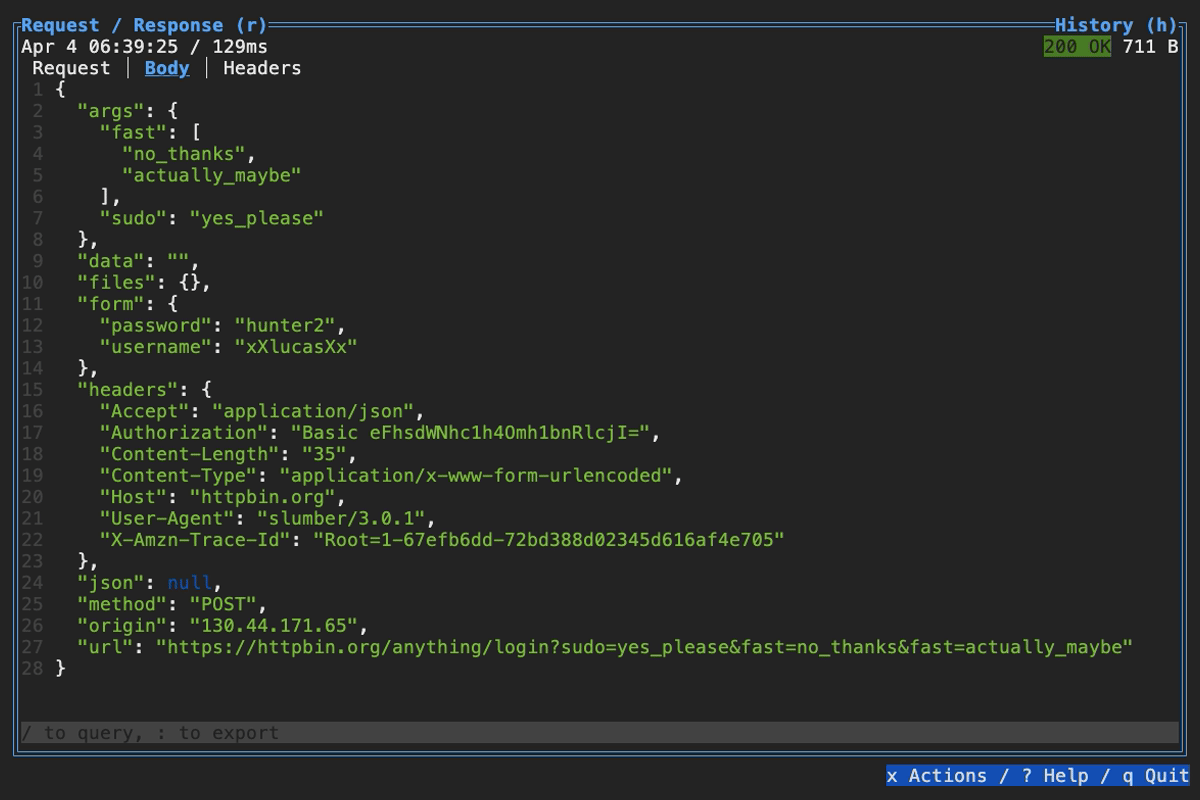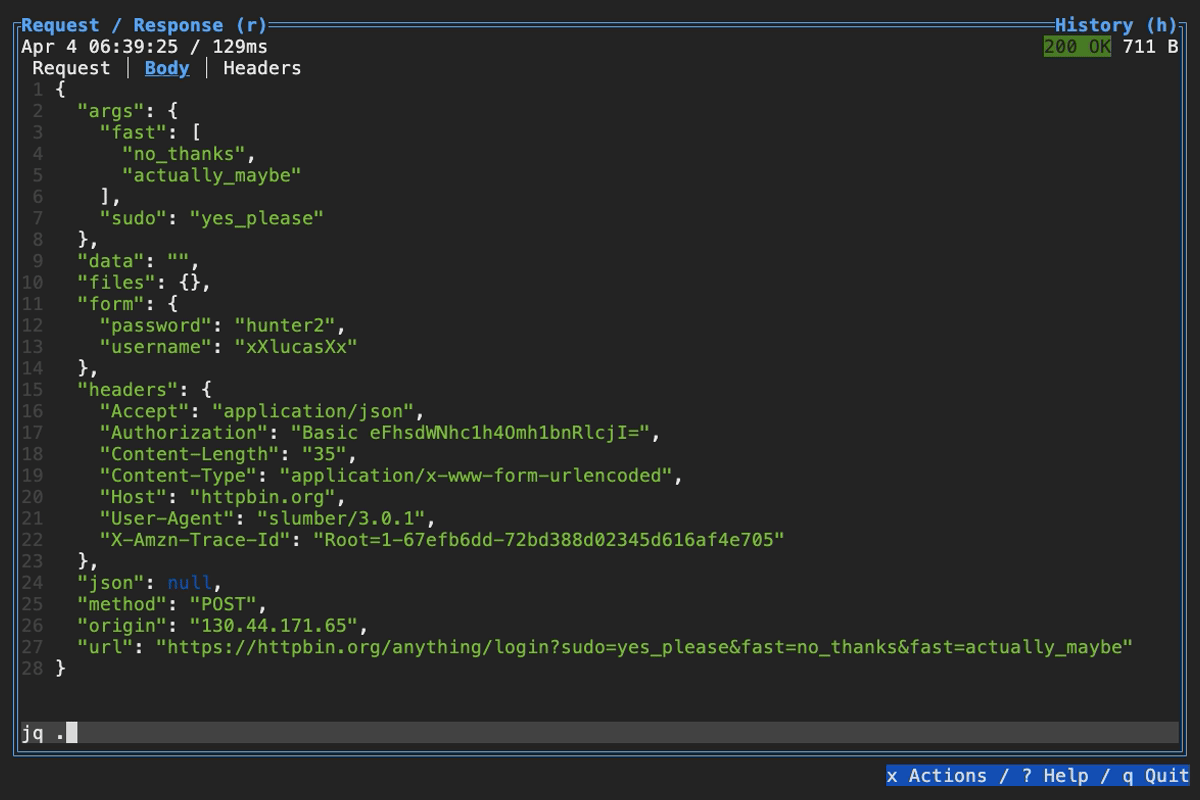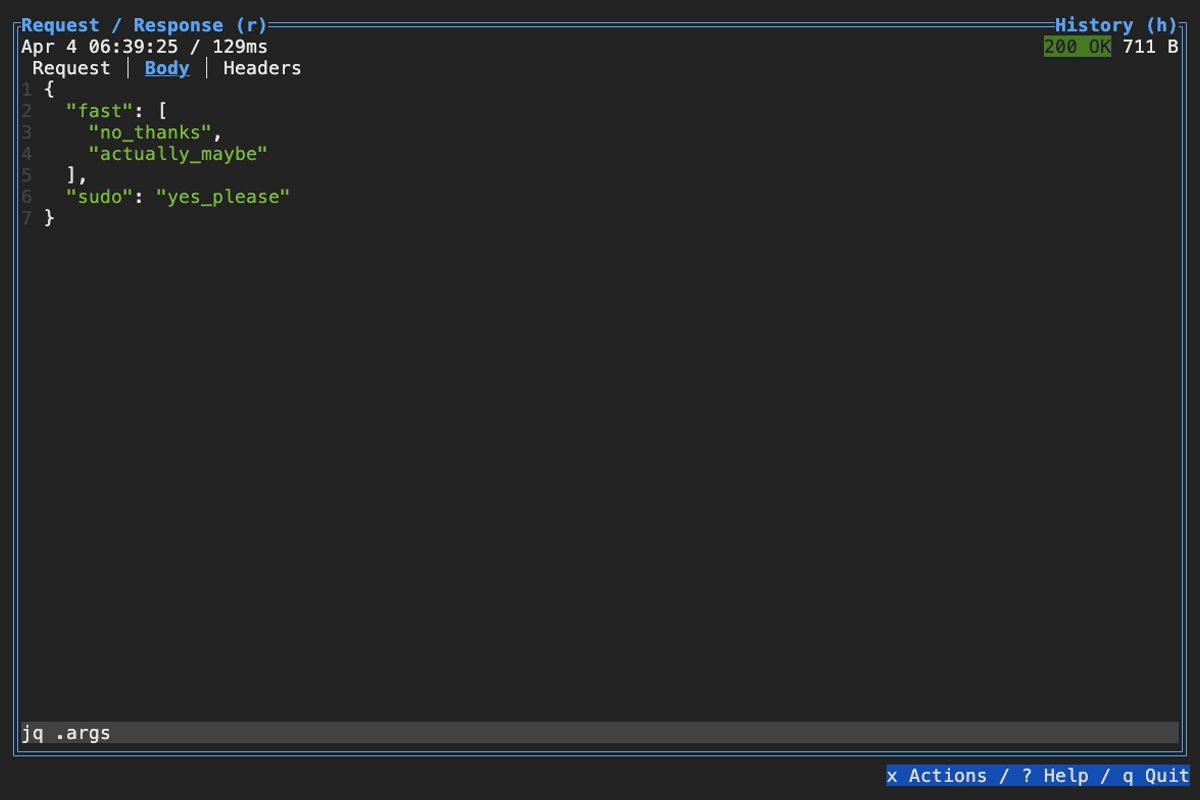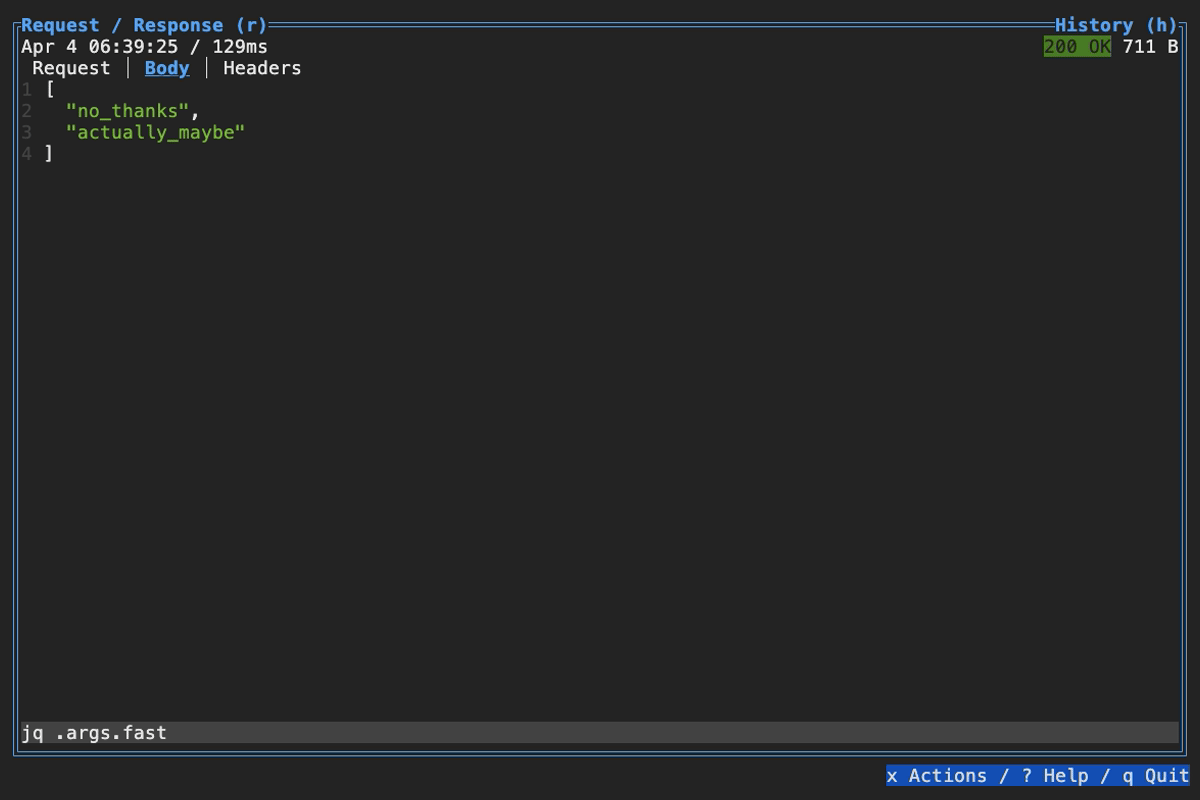
Example of querying with jq
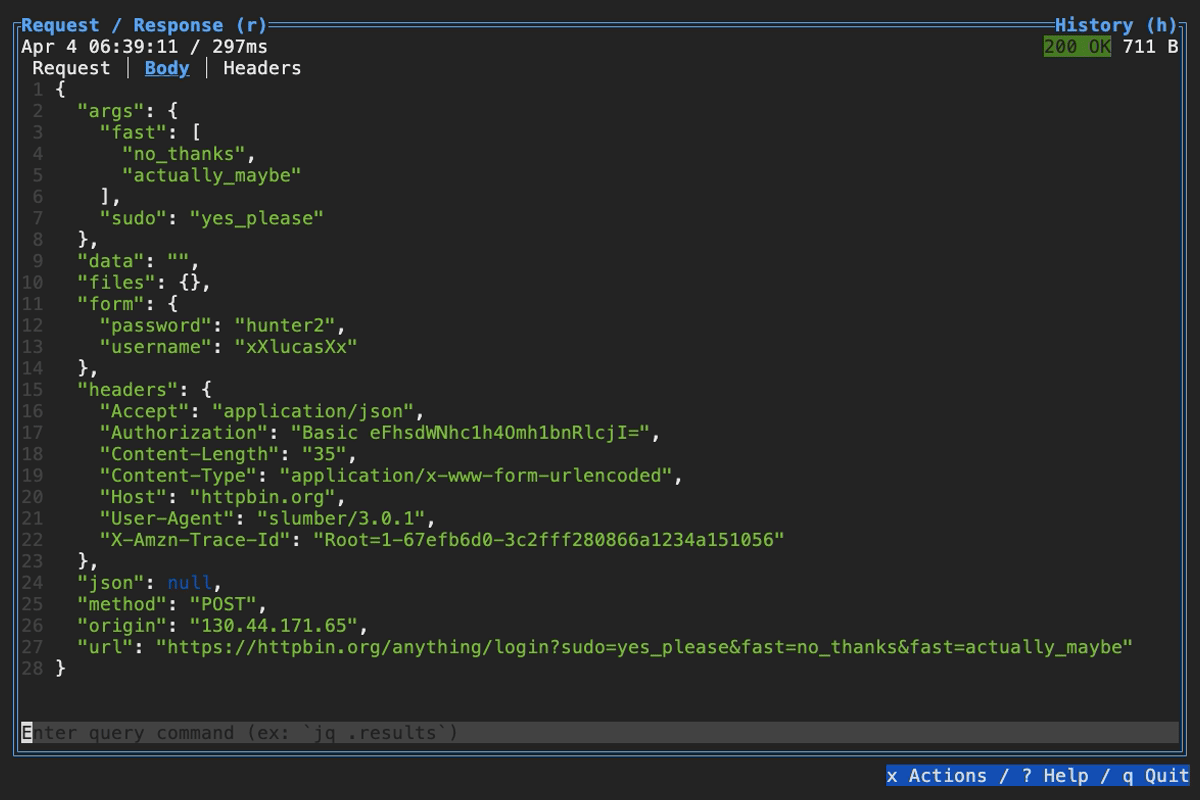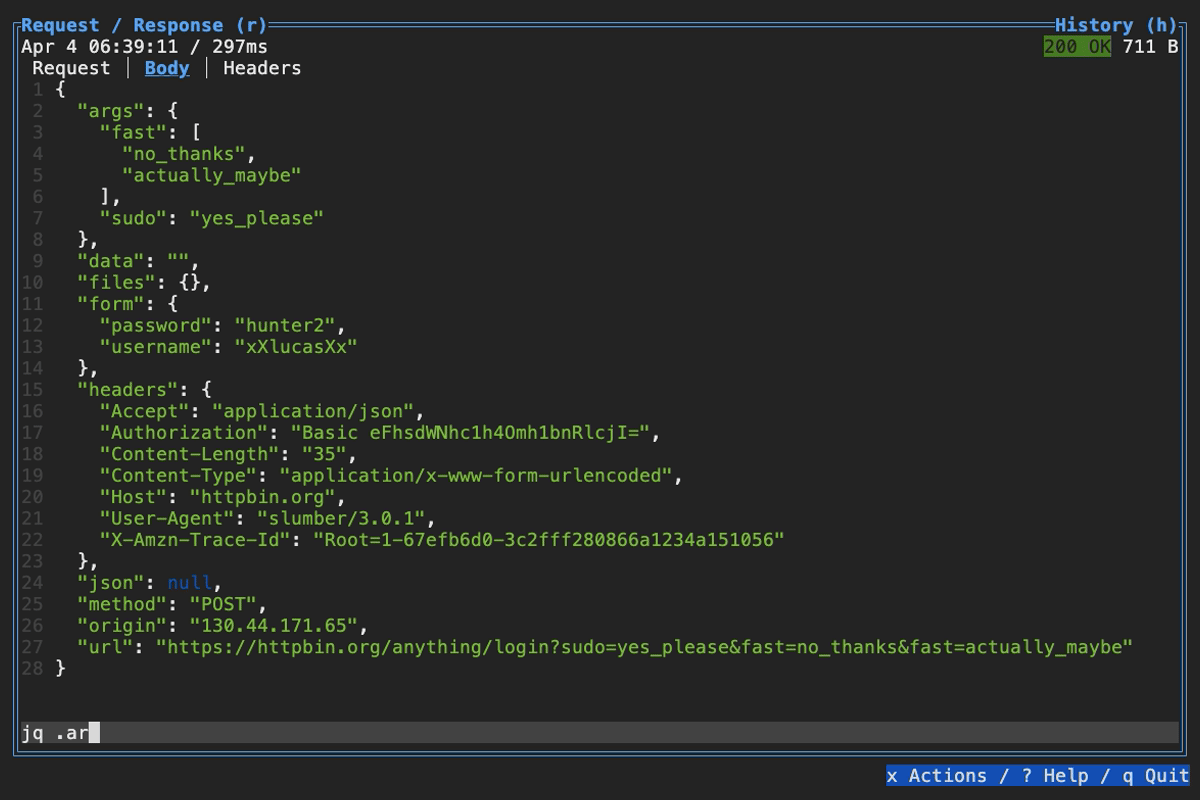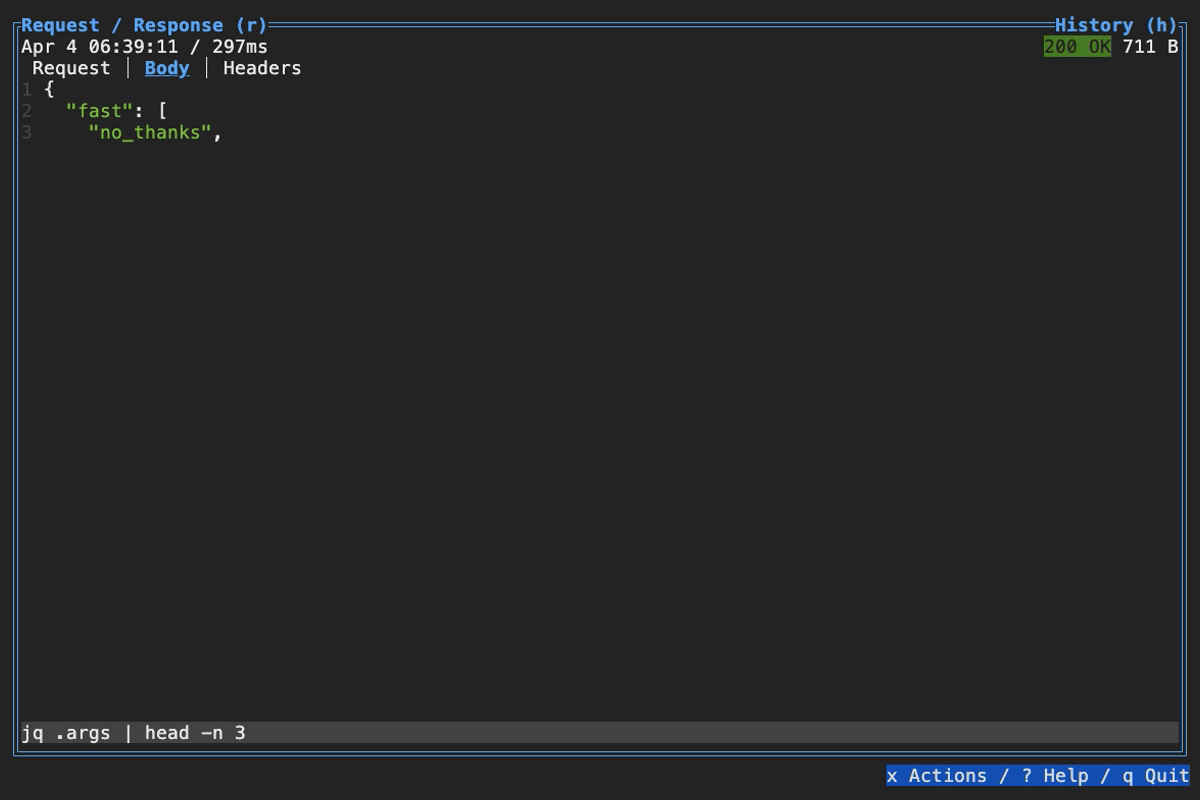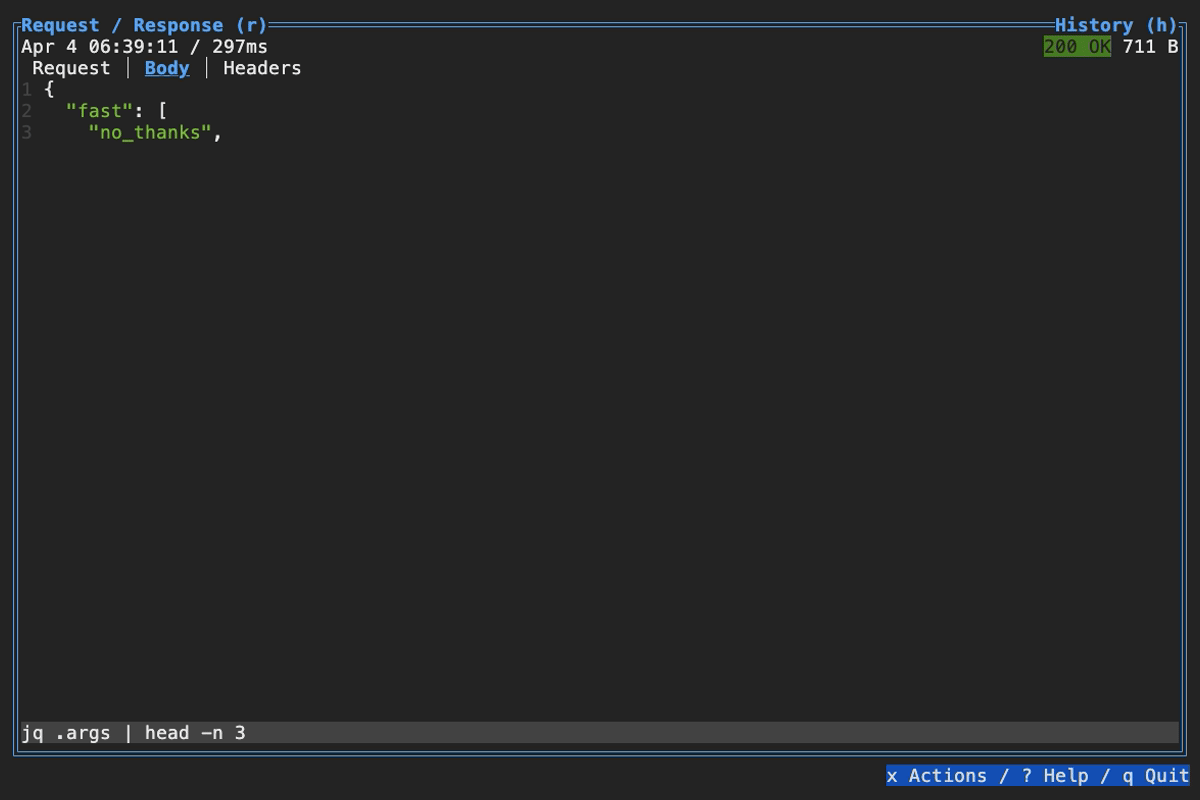
Example of using pipes in a query command
Exporting data
Keep in mind that your queries are being executed as shell commands on your system. You should avoid running any commands that interact with the file system, such as using > or < to pipe to/from files. However, if you want to export response data from Slumber, you can do so with the export command palette. To open the export palette, select the Response pane and press the export key binding (: by default). Then enter any shell command, which will receive the response body as stdin.
Note: For text bodies, whatever text is visible in the response pane is what will be passed to stdin. So if you have a query applied, the queried body will be exported. For binary bodies, the original bytes will be exported.
Some useful commands for exporting data:
tee > response.json- Save the response toresponse.jsonteetakes data from stdin and sends it to zero or more files as well as stdout. Another way to write this would betee response.json
pbcopy- Copy the body to the clipboard (MacOS only - search online to find the correct command for your platform)
Remember: This is a real shell, so you can pipe through whatever transformation commands you want here!
Default command
You can set the default command to query with via the commands.default_query config field. This accepts either a single string to set it for all content types, or a MIME map to set different defaults based on the response content type. For example, to default to jq for all JSON responses:
commands:
default_query:
json: jq
Which shell does Slumber use?
By default, Slumber executes your command via sh -c on Unix and cmd /S /C on Windows. You can customize this via the commands.shell configuration field. For example, to use fish instead of sh:
commands:
shell: [fish, -c]
If you don't want to execute via any shell, you can set it to []. In this case, query commands will be parsed via shell-words and executed directly. For example, jq .args will be parsed into ["jq", ".args"], then jq will be executed with a single argument: .args. This of course means you won't get access to shell features such as |, but it provides better cross-platform portability.
Command Line Interface
While Slumber is primary intended as a TUI, it also provides a Command Line Interface (CLI). The CLI can be used to send requests, just like the TUI. It also provides some utility commands for functionality not available in the TUI. For a full list of available commands see the side bar or run:
slumber help
Some common CLI use cases:
- Send requests
- Import from an external format
- Generate request in an external format (e.g. curl)
- View Slumber configuration/metadata
Examples
The Slumber CLI can be composed with other CLI tools, making it a powerful tool for scripting and bulk tasks. Here are some examples of how to use it with common tools.
Note: These examples are written for a POSIX shell (bash, zsh, etc.). It assumes some basic familiarity with shell features such as pipes. Unfortunately I have no shell experience with Windows so I can't help you there :(
Filtering responses with jq
Let's say you want to fetch the name of each fish from your fish-tracking service. Here's your collection file:
requests:
list_fish: !request
method: GET
url: "https://myfishes.fish/fishes"
This endpoint returns a response like:
[
{
"kind": "barracuda",
"name": "Jimmy"
},
{
"kind": "striped bass",
"name": "Balthazar"
},
{
"kind": "rockfish",
"name": "Maureen"
}
]
You can fetch this response and filter it down to just the names:
slumber rq list_fish | jq -r '.[].name'
And the output:
Jimmy
Balthazar
Maureen
Running requests in parallel with xargs
Building on the previous example, let's say you want to fetch details on each fish returned from the list response. We'll add a get_fish recipe to the collection. By default, the fish name will come from a prompt:
chains:
fish_name:
source: !prompt
message: "Which fish?"
requests:
list_fish: !request
method: GET
url: "https://myfishes.fish/fishes"
get_fish: !request
method: GET
url: "https://myfishes.fish/fishes/{{chains.fish_name}}"
We can use xargs and the -o flag of slumber request to fetch details for each fish in parallel:
slumber rq list_fish | jq -r '.[].name' > fish.txt
cat fish.txt | xargs -L1 -I'{}' -P3 slumber rq get_fish -o chains.fish_name={} --output {}.json
Let's break this down:
-L1means to consume one argument (in this case, one fish name) per invocation ofslumber-I{}sets the substitution string, i.e. the string that will be replaced with each argument-P3tellsxargsthe maximum number of processes to run concurrently, which in this case means the maximum number of concurrent requests- Everything else is the
slumbercommand-o chains.fish_name={}chains.fish_name` with the argument from the file, so it doesn't prompt for a name--output {}.jsonwrites to a JSON file with the fish's name (e.g.Jimmy.json)
Subcommands
slumber collections
View and manipulate stored collection history/state. Slumber uses a local database to store all request/response history, as well as UI state and other persisted values. As a user, you rarely have to worry about this. The most common scenario in which you do have to is if you've renamed a collection file and want to migrate the history to match the new path. See here for how to migrate collection files.
See slumber collections --help for more options.
slumber db
Access the local Slumber database file. This is an advanced command; most users never need to manually view or modify the database file. By default this executes sqlite3 and thus requires sqlite3 to be installed.
Open a shell to the database:
slumber db
Run a single query and exit:
slumber db 'select 1'
slumber generate
Generate an HTTP request in an external format. Currently the only supported format is cURL.
Overrides
The generate subcommand supports overriding template values in the same that slumber request does. See the request subcommand docs for more.
See slumber generate --help for more options.
Examples
Given this request collection:
profiles:
production:
data:
host: https://myfishes.fish
requests:
list_fish: !request
method: GET
url: "{{host}}/fishes"
query:
- big=true
slumber generate curl --profile production list_fishes
slumber generate curl --profile production list_fishes -o host=http://localhost:8000
slumber history
View and modify your Slumber request history. Slumber stores every command sent from the TUI in a local SQLite database (requests are not stored remotely). You can find the database file with slumber show paths db.
You can use the slumber history subcommand to browse and delete request history.
slumber history list
List requests in a table.
slumber history list # List all requests for the current collection
slumber history list --all # List all requests for all collections
slumber history list login # List all requests for the "login" recipe
slumber history list login -p dev # List all requests for "login" under the "dev" profile
slumber history get
Show a single request/response from history.
slumber history get login # Get the most recent request/response for "login"
slumber history get 548ba3e7-3b96-4695-9856-236626ea0495 # Get a particular request/response by ID (IDs can be retrieved from the `list` subcommand)
slumber history delete
Delete requests from history by ID.
slumber history delete 548ba3e7-3b96-4695-9856-236626ea0495
# Delete multiple requests
slumber history list login --id-only | xargs slumber history delete
slumber import
Generate a Slumber collection file based on an external format.
See slumber import --help for more options.
Disclaimer
Importers are approximate. They'll give the you skeleton of a collection file, but don't expect 100% equivalency. They save a lot of tedious work for you, but you'll generally still need to do some manual work on the collection file to get what you want.
Formats
Supported formats:
- Insomnia
- OpenAPI v3.0 and OpenAPI v3.1
- VSCode
.rest - JetBrains
.http
Examples
The general format is:
slumber import <format> <input> [output]
Possible inputs are:
-for stdin- Path to a local file
- URL to download via HTTP
For example, to import from an Insomnia collection insomnia.json:
slumber import insomnia insomnia.json slumber.yml
# Or, to read from stdin and print to stdout
slumber import insomnia - < insomnia.json
Or to import an OpenAPI spec from a server:
slumber import openapi https://petstore3.swagger.io/api/v3/openapi.json slumber.yml
Requested formats:
If you'd like another format supported, please open an issue.
slumber new
Generate a new Slumber collection file. The new collection will have some example data predefined.
Examples
# Generate and use a new collection at the default path of slumber.yml
slumber new
slumber
# Generate and use a new collection at a custom path
slumber new my-collection.yml
slumber -f my-collection.yml
slumber request
Send an HTTP request. There are many use cases to which the CLI is better suited than the TUI for sending requests, including:
- Sending a single one-off request
- Sending many requests in parallel
- Automating requests in a script
- Sharing requests with others
See slumber request --help for more options.
Overrides
You can manually override template values using CLI arguments. This means the template renderer will use the override value in place of calculating it. For example:
slumber request list_fishes --override host=https://dev.myfishes.fish
This can also be used to override chained values:
slumber request login --override chains.password=hunter2
Exit Code
By default, the CLI returns exit code 1 if there is a fatal error, e.g. the request failed to build or a network error occurred. If an HTTP response was received and parsed, the process will exit with code 0, regardless of HTTP status.
If you want to set the exit code based on the HTTP response status, use the flag --exit-code.
| Code | Reason |
|---|---|
| 0 | HTTP response received |
| 1 | Fatal error |
| 2 | HTTP response had status >=400 (with --exit-code) |
Examples
Given this request collection:
profiles:
production:
data:
host: https://myfishes.fish
requests:
list_fish: !request
method: GET
url: "{{host}}/fishes"
query:
- big=true
slumber request --profile production list_fishes
slumber rq -p production list_fishes # rq is a shorter alias
slumber -f fishes.yml -p production list_fishes # Different collection file
slumber show
Print metadata about Slumber.
See slumber show --help for more options.
Examples
slumber show paths # Show paths of various Slumber data files/directories
slumber show config # Print global configuration
slumber show config --edit # Edit global configuration
slumber show collection # Print collection file
slumber show collection --edit # Edit collection file
Templates
Templates enable dynamic string/binary construction. Slumber's template language is relatively simple, compared to complex HTML templating languages like Handlebars or Jinja. The goal is to be intuitive and unsurprising. It doesn't support complex features like loops, conditionals, etc.
Most string values in a request collection (e.g. URL, request body, etc.) are templates. Map keys (e.g. recipe ID, profile ID) are not templates; they must be static strings.
The syntax for injecting a dynamic value into a template is double curly braces {{...}}. The contents inside the braces tell Slumber how to retrieve the dynamic value.
This guide serves as a functional example of how to use templates. For detailed information on options available, see the API reference.
A note on YAML string syntax
One of the advantages (and disadvantages) of YAML is that it has a number of different string syntaxes. This enables you to customize your templates according to your specific needs around the behavior of whitespace and newlines. See YAML's string syntaxes and yaml-multiline.info for more info on YAML strings.
A Basic Example
Let's start with a simple example. Let's say you're working on a fish-themed website, and you want to make requests both to your local stack and the deployed site. Templates, combined with profiles, allow you to easily switch between hosts:
Note: for the purposes of these examples, I've made up some theoretical endpoints and responses, following standard REST practice. This isn't a real API but it should get the point across.
Additionally, these examples will use the CLI because it's easy to demonstrate in text. All these concepts apply equally to the TUI.
profiles:
local:
data:
host: http://localhost:5000
production:
data:
host: https://myfishes.fish
requests:
list_fish: !request
method: GET
url: "{{host}}/fishes"
query:
- big=true
Now you can easily select which host to hit. In the TUI, this is done via the Profile list. In the CLI, use the --profile option:
> slumber request --profile local list_fish
# http://localhost:5000/fishes
# Only one fish :(
[{"id": 1, "kind": "tuna", "name": "Bart"}]
> slumber request --profile production list_fish
# https://myfishes.fish/fishes
# More fish!
[
{"id": 1, "kind": "marlin", "name": "Kim"},
{"id": 2, "kind": "salmon", "name": "Francis"}
]
Nested Templates
What if you need a more complex chained value? Let's say the endpoint to get a fish requires the fish ID to be in the format fish_{id}. Why? Don't worry about it. Fish are particular. Templates support nesting implicitly. You can use this to compose template values into more complex strings. Just be careful not to trigger infinite recursion!
profiles:
local:
data:
host: http://localhost:5000
fish_id: "fish_{{chains.fish_id}}"
chains:
fish_id:
source: !request
recipe: create_fish
selector: $.id
requests:
create_fish: !request
method: POST
url: "{{host}}/fishes"
body: !json { "kind": "barracuda", "name": "Jimmy" }
get_fish: !request
method: GET
url: "{{host}}/fishes/{{fish_id}}"
And let's see it in action:
> slumber request -p local create_fish
# http://localhost:5000/fishes
{"id": 2, "kind": "barracuda", "name": "Jimmy"}
> slumber request -p local get_fish
# http://localhost:5000/fishes/fish_2
{"id": "fish_2", "kind": "barracuda", "name": "Jimmy"}
Binary Templates
While templates are mostly useful for generating strings, they can also generate binary data. This is most useful for sending binary request bodies. Some fields (e.g. URL) do not support binary templates because they need valid text; in those cases, if the template renders to non-UTF-8 data, an error will be returned. In general, if binary data can be supported, it is.
Note: Support for binary form data is currently incomplete. You can render binary data from templates, but forms must be constructed manually. See #235 for more info.
profiles:
local:
data:
host: http://localhost:5000
fish_id: "cod_father"
chains:
fish_image:
source: !file
path: ./cod_father.jpg
requests:
set_fish_image: !request
method: POST
url: "{{host}}/fishes/{{fish_id}}/image"
headers:
Content-Type: image/jpg
body: "{{chains.fish_image}}"
Chains
Chains are Slumber's most powerful feature. They allow you to dynamically build requests based on other responses, shell commands, and more.
Chains in Practice
The most common example of a chain is with a login request. You can define a recipe to log in to a service using username+password, then get the returned API token to authenticate subsequent requests. Of course, we don't want to store our credentials in Slumber file, so we can also use chains to fetch those. Let's see this in action:
chains:
username:
source: !file
path: ./username.txt
password:
source: !file
path: ./password.txt
auth_token:
source: !request
recipe: login
selector: $.token
requests:
# This returns a response like {"token": "abc123"}
login: !request
method: POST
url: "https://myfishes.fish/login"
body:
!json {
"username": "{{chains.username}}",
"password": "{{chains.password}}",
}
get_user: !request
method: GET
url: "https://myfishes.fish/current-user"
authentication: !bearer "{{chains.auth_token}}"
For more info on the
selectorfield, see Data Extraction via JSONPath
Automatically Executing the Upstream Request
By default, the chained request (i.e. the "upstream" request) has to be executed manually to get the login token. You can have the upstream request automatically execute using the trigger field:
chains:
auth_token:
source: !request
recipe: login
# Execute only if we've never logged in before
trigger: !no_history
selector: $.token
---
chains:
auth_token:
source: !request
recipe: login
# Execute only if the latest response is older than a day. Useful if your
# token expires after a fixed amount of time
trigger: !expire 1d
selector: $.token
---
chains:
auth_token:
source: !request
recipe: login
# Always execute
trigger: !always
selector: $.token
For more detail about the various trigger variants, including the syntax of the expire variant, see the API docs.
Chaining Chains
Chains on their own are powerful enough, but what makes them really cool is that the arguments to a chain are templates in themselves, meaning you can use nested templates to chain chains to other chains! Wait, what?
Let's say the login response doesn't return JSON, but instead the response looks like this:
token:abc123
Clearly this isn't a well-designed API, but sometimes that's all you get. You can use a nested chain with cut to parse this:
chains:
username:
source: !file
path: ./username.txt
password_encrypted:
source: !file
path: ./password.txt
password:
source: !command
command:
auth_token_raw:
source: !request
recipe: login
auth_token:
source: !command
command: ["cut", "-d':'", "-f2"]
stdin: "{{chains.auth_token_raw}}"
requests:
login: !request
method: POST
url: "https://myfishes.fish/login"
body:
!json {
"username": "{{chains.username}}",
"password": "{{chains.password}}",
}
get_user: !request
method: GET
url: "https://myfishes.fish/current-user"
authentication: !bearer "{{chains.auth_token}}"
This means you can use external commands to perform any manipulation on data that you want.
Data Extraction via JSONPath
Chains support querying data structures to transform or reduce response data. THis is done via the selector field of a chain.
Regardless of data format, querying is done via JSONPath. For non-JSON formats, the data will be converted to JSON, queried, and converted back. This keeps querying simple and uniform across data types.
Querying Chained Values
Here's some examples of using queries to extract data from a chained value. Let's say you have two chained value sources. The first is a JSON file, called creds.json. It has the following contents:
{ "user": "fishman", "pw": "hunter2" }
We'll use these credentials to log in and get an API token, so the second data source is the login response, which looks like so:
{ "token": "abcdef123" }
chains:
username:
# Slumber knows how to query this file based on its extension
source: !file
path: ./creds.json
selector: $.user
password:
source: !file
path: ./creds.json
selector: $.pw
auth_token:
source: !request
recipe: login
selector: $.token
requests:
login: !request
method: POST
url: "https://myfishes.fish/anything/login"
body:
!json {
"username": "{{chains.username}}",
"password": "{{chains.password}}",
}
get_user: !request
method: GET
url: "https://myfishes.fish/anything/current-user"
query:
- auth={{chains.auth_token}}
While this example simple extracts inner fields, JSONPath can be used for much more powerful transformations. See the JSONPath docs or this JSONPath editor for more examples.
More Powerful Querying with Nested Chains
If JSONPath isn't enough for the data extraction you need, you can use nested chains to filter with whatever external programs you want. For example, if you want to use jq instead:
chains:
username:
source: !file
path: ./creds.json
selector: $.user
password:
source: !file
path: ./creds.json
selector: $.pw
auth_token_raw:
source: !request
recipe: login
auth_token:
source: !command
command: [ "jq", ".token" ]
stdin: "{{chains.auth_token_raw}}
requests:
login: !request
method: POST
url: "https://myfishes.fish/anything/login"
body: !json
{
"username": "{{chains.username}}",
"password": "{{chains.password}}"
}
get_user: !request
method: GET
url: "https://myfishes.fish/anything/current-user"
query:
- auth={{chains.auth_token}}
You can use this capability to manipulate responses via grep, awk, or any other program you like.
Collection Reuse & Inheritance
The Problem
Let's start with an example of something that sucks. Let's say you're making requests to a fish-themed JSON API, and it requires authentication. Gotta protect your fish! Your request collection might look like so:
profiles:
production:
data:
host: https://myfishes.fish
fish_id: 6
chains:
token:
source: !file
path: ./api_token.txt
fish_id:
source: !prompt
message: Fish ID
requests:
list_fish: !request
method: GET
url: "{{host}}/fishes"
query:
- big=true
headers:
Accept: application/json
authentication: !bearer "{{chains.token}}"
get_fish: !request
method: GET
url: "{{host}}/fishes/{{fish_id}}"
headers:
Accept: application/json
authentication: !bearer "{{chains.token}}"
The Solution
You've heard of DRY, so you know this is bad. Every new request recipe requires re-specifying the headers, and if anything about the authorization changes, you have to change it in multiple places.
You can easily re-use components of your collection using YAML's merge feature.
profiles:
production:
data:
host: https://myfishes.fish
chains:
token:
source: !file
path: ./api_token.txt
fish_id:
source: !prompt
message: Fish ID
# The name here is arbitrary, pick any name you like. Make sure it starts with
# . to avoid errors about an unknown field
.request_base: &request_base
headers:
Accept: application/json
authentication: !bearer "{{chains.token}}"
requests:
list_fish: !request
<<: *request_base
method: GET
url: "{{host}}/fishes"
query:
- big=true
get_fish: !request
<<: *request_base
method: GET
url: "{{host}}/fishes/{{chains.fish_id}}"
Great! That's so much cleaner. Now each recipe can inherit whatever base properties you want just by including <<: *request_base. This is still a bit repetitive, but it has the advantage of being explicit. You may have some requests that don't want to include those values.
Recursive Inheritance
But wait! What if you have a new request that needs an additional header? Unfortunately, YAML's merge feature does not support recursive merging. If you need to extend the headers map from the base request, you'll need to pull that map in manually:
profiles:
production:
data:
host: https://myfishes.fish
chains:
token:
source: !file
path: ./api_token.txt
fish_id:
source: !prompt
message: Fish ID
.request_base: &request_base
headers: &headers_base # This will let us pull in the header map
Accept: application/json
authentication: !bearer "{{chains.token}}"
requests:
list_fish: !request
<<: *request_base
method: GET
url: "{{host}}/fishes"
query:
- big=true
get_fish: !request
<<: *request_base
method: GET
url: "{{host}}/fishes/{{chains.fish_id}}"
create_fish: !request
<<: *request_base
method: POST
url: "{{host}}/fishes"
headers:
<<: *headers_base
Host: myfishes.fish
body: !json { "kind": "barracuda", "name": "Jimmy" }
Importing External Collections
See the slumber import subcommand.
Database & Persistence
Note: This is an advanced feature. The vast majority of users can use Slumber all they want without even knowing the database exists.
Slumber uses a SQLite database to persist requests and responses. The database also stores UI state that needs to be persisted between sessions. This database exists exclusively on your device. The Slumber database is never uploaded to the cloud or shared in any way. Slumber does not make any network connections beyond the ones you define and execute yourself. You own your data; I don't want it.
Data for all your Slumber collections are stored in a single file. To find this file, run slumber show paths, and look for the Database entry. I encourage you to browse this file if you're curious; it's pretty simple and there's nothing secret in it. Keep in mind though that the database format is NOT considered part of Slumber's API contract. It may change at any time, including the database path moving or tables be changed or removed, even in a minor or patch release.
Controlling Persistence
By default, all requests made in the TUI are stored in the database. This enables the history browser, allowing you to browse past requests. While generally useful, this may not be desired in all cases. However, there are some cases where you may not want requests persisted:
- The request or response may contain sensitive data
- The response is very large and impacts app performance
You can disable persistence for a single recipe by setting persist: false for that recipe. You can disable history globally by setting persist: false in the global config file. Note that this only disables request persistence. UI state, such as selection state for panes and checkboxes, is still written to the database.
NOTE: Disabling persistence does not delete existing request history. See here for how to do that.
Slumber will generally continue to work just fine with request persistence disabled. Requests and responses are still cached in memory, they just aren't written to the database anymore and therefore can't be recovered after the current session is closed. If you disable persistence, you will notice a few impacts on functionality:
- The history modal will only show requests made during the current session
- Chained requests can only access responses from the current session. Consider adding
trigger: !no_historyto the request to automatically refetch it on new sessions.
Unlike the TUI, requests made from the CLI are not persisted by default. This is because the CLI is often used for scripting and bulk requests. Persisting these requests could have major performance impacts for little to no practical gain. Pass the --persist flag to slumber request to persist a CLI request.
Deleting Request History
There are a few ways to delete requests from history:
- In the TUI. Open the actions menu while a request/response is selected to delete that request. From the recipe list/recipe pane, you can delete all requests for that recipe.
- The
slumber history deletecan delete one or more commands at a time. Combine withslumber history listfor bulk deletes:slumber history list login --id-only | xargs slumber history delete - Manually modifying the database. You can access the DB with
slumber db. While this is not an officially supported technique (as the DB schema may change without warning), it's simple enough to navigate if you want to performance bulk deletes with custom criteria.
Migrating Collections
As all Slumber collections' histories are stored in the same SQLite database, each collection gets a unique UUID generated when it is first accessed. This UUID is used to persist request history and other data related to the collection. This UUID is bound to the collection's path. If you move a collection file, a new UUID will be generated and it will be unlinked from its previous history. If you want to retain that history, you can migrate data from the old ID to the new one like so:
slumber collections migrate slumber-old.yml slumber-new.yml
If you don't remember the path of the old file, you can list all known collections with:
slumber collections list
Request Collection
The request collection is the primary configuration for Slumber. It defines which requests can be made, and how to make them. When running a slumber instance, a single collection file is loaded. If you want to work with multiple collections at once, you'll have to run multiple instances of Slumber.
Collection files are designed to be sharable, meaning you can commit them to your Git repo. The most common pattern is to create one collection per API repo, and check it into the repo so other developers of the API can use the same collection. This makes it easy for any new developer or user to learn how to use an API.
Format & Loading
A collection is defined as a YAML file. When you run slumber, it will search the current directory and its parents for the following default collection files, in order:
slumber.ymlslumber.yaml.slumber.yml.slumber.yaml
Whichever of those files is found first will be used. For any given directory, if no collection file is found there, it will recursively go up the directory tree until we find a collection file or hit the root directory. If you want to use a different file for your collection (e.g. if you want to store multiple collections in the same directory), you can override the auto-search with the --file (or -f) command line argument. You can also pass a directory to --file to have it search that directory instead of the current one. E.g.:
slumber --file my-collection.yml
slumber --file ../another-project/
Fields
A request collection supports the following top-level fields:
| Field | Type | Description | Default |
|---|---|---|---|
profiles | mapping[string, Profile] | Static template values | {} |
requests | mapping[string, RequestRecipe] | Requests Slumber can send | {} |
chains | mapping[string, Chain] | Complex template values | {} |
In addition to these fields, any top-level field beginning with . will be ignored. This can be combined with YAML anchors to define reusable components in your collection file.
Examples
profiles:
local:
name: Local
data:
host: http://localhost:5000
user_guid: abc123
prd:
name: Production
data:
host: https://httpbin.org
user_guid: abc123
chains:
username:
source: !file
path: ./username.txt
password:
source: !prompt
message: Password
sensitive: true
auth_token:
source: !request
recipe: login
selector: $.token
# Use YAML anchors for de-duplication. Normally unknown fields in the
# collection trigger an error; the . prefix tells Slumber to ignore this field
.base: &base
headers:
Accept: application/json
requests:
login: !request
<<: *base
method: POST
url: "{{host}}/anything/login"
body:
!json {
"username": "{{chains.username}}",
"password": "{{chains.password}}",
}
# Folders can be used to keep your recipes organized
users: !folder
requests:
get_user: !request
<<: *base
name: Get User
method: GET
url: "{{host}}/anything/current-user"
authentication: !bearer "{{chains.auth_token}}"
update_user: !request
<<: *base
name: Update User
method: PUT
url: "{{host}}/anything/current-user"
authentication: !bearer "{{chains.auth_token}}"
body: !json { "username": "Kenny" }
Profile
A profile is a collection of static template values. It's useful for configuring and switching between multiple different environments/settings/etc. Profile values are all templates themselves, so nested values can be used.
Fields
| Field | Type | Description | Default |
|---|---|---|---|
name | string | Descriptive name to use in the UI | Value of key in parent |
default | boolean | Use this profile in the CLI when --profile isn't provided | null |
data | mapping[string, Template] | Fields, mapped to their values | {} |
Examples
profiles:
local:
name: Local
data:
host: localhost:5000
url: "https://{{host}}"
user_guid: abc123
Template
A template is represented in YAML as a normal string, and thus supports all of YAML's string syntaxes. Templates receive post-processing that injects dynamic values into the string. A templated value is represented with {{...}}.
Templates can generally be used in any value in a request recipe (not in keys), as well as in profile values and chains. This makes them very powerful, because you can compose templates with complex transformations.
For more detail on usage and examples, see the user guide page on templates.
Template Sources
There are several ways of sourcing templating values:
| Source | Syntax | Description | Default |
|---|---|---|---|
| Profile Field | {{field_name}} | Static value from a profile | Error if unknown |
| Environment Variable | {{env.VARIABLE}} | Environment variable from parent shell/process | "" |
| Chain | {{chains.chain_id}} | Complex chained value | Error if unknown |
Escape Sequences
In some scenarios you may want to use the {{ sequence to represent those literal characters, rather than the start of a template key. To achieve this, you can escape the sequence with an underscore inside it, e.g. {_{. If you want the literal string {_{, then add an extra underscore: {__{.
| Template | Parses as |
|---|---|
{_{this is raw text}} | ["{{this is raw text}}"] |
{_{{field1}} | ["{", field("field1")] |
{__{{field1}} | ["{__", field("field1")] |
{_ | ["{_"] (no escaping) |
Examples
# Profile value
"hello, {{location}}"
---
# Multiple dynamic values
"{{greeting}}, {{location}}"
---
# Environment variable
"hello, {{env.LOCATION}}"
---
# Chained value
"hello, {{chains.where_am_i}}"
---
# No dynamic values
"hello, world!"
---
# Escaped template key
"{_{this is raw text}}"
Request Recipe
A request recipe defines how to make a particular request. For a REST API, you'll typically create one request recipe per endpoint. Other HTTP tools often call this just a "request", but that name can be confusing because "request" can also refer to a single instance of an HTTP request. Slumber uses the term "recipe" because it's used to render many requests. The word "template" would work as a synonym here, although we avoid that term here because it also refers to string templates.
Recipes can be organized into folders. This means your set of recipes can form a tree structure. Folders are purely organizational, and don't impact the behavior of their child recipes at all.
The IDs of your folders/recipes must be globally unique. This means you can't have two recipes (or two folders, or one recipe and one folder) with the same associated key, even if they are in different folders. This restriction makes it easy to refer to recipes unambiguously using a single ID, which is helpful for CLI usage and data storage.
Recipe Fields
The tag for a recipe is !request (see examples).
| Field | Type | Description | Default |
|---|---|---|---|
name | string | Descriptive name to use in the UI | Value of key in parent |
method | string | HTTP request method | Required |
url | Template | HTTP request URL | Required |
query | QueryParameters | URL query parameters | {} |
headers | mapping[string, Template] | HTTP request headers | {} |
authentication | Authentication | Authentication scheme | null |
body | RecipeBody | HTTP request body | null |
persist | boolean | Enable/disable request persistence. Read more | true |
Folder Fields
The tag for a folder is !folder (see examples).
| Field | Type | Description | Default |
|---|---|---|---|
name | string | Descriptive name to use in the UI | Value of key in parent |
children | mapping[string, RequestRecipe] | Recipes organized under this folder | {} |
Examples
recipes:
login: !request
name: Login
method: POST
url: "{{host}}/anything/login"
headers:
accept: application/json
query:
- root_access=yes_please
body:
!json {
"username": "{{chains.username}}",
"password": "{{chains.password}}",
}
fish: !folder
name: Users
requests:
create_fish: !request
method: POST
url: "{{host}}/fishes"
body: !json { "kind": "barracuda", "name": "Jimmy" }
list_fish: !request
method: GET
url: "{{host}}/fishes"
query:
- big=true
Query Parameters
Query parameters are a component of a request URL. They provide additional information to the server about a request. In a request recipe, query parameters can be defined in one of two formats:
- Mapping of
key: value - List of strings, in the format
<key>=<value>
The mapping format is typically more readable, but the list format allows you to define the same query parameter multiple times. In either format, the key is treated as a plain string but the value is treated as a template.
Note: If you need to include a
=in your parameter name, you'll need to use the mapping format. That means there is currently no support for multiple instances of a parameter with=in the name. This is very unlikely to be a restriction in the real world, but if you need support for this please open an issue.
Examples
recipes:
get_fishes_mapping: !request
method: GET
url: "{{host}}/get"
query:
big: true
color: red
name: "{{name}}"
get_fishes_list: !request
method: GET
url: "{{host}}/get"
query:
- big=true
- color=red
- color=blue
- name={{name}}
Authentication
Authentication provides shortcuts for common HTTP authentication schemes. It populates the authentication field of a recipe. There are multiple source types, and the type is specified using YAML's tag syntax.
Variants
| Variant | Type | Value |
|---|---|---|
!basic | Basic Authentication | Basic authentication credentials |
!bearer | string | Bearer token |
Basic Authentication
Basic authentication contains a username and optional password.
| Field | Type | Description | Default |
|---|---|---|---|
username | string | Username | Required |
password | string | Password | "" |
Examples
# Basic auth
requests:
create_fish: !request
method: POST
url: "{{host}}/fishes"
body: !json { "kind": "barracuda", "name": "Jimmy" }
authentication: !basic
username: user
password: pass
---
# Bearer token auth
chains:
token:
source: !file
path: ./token.txt
requests:
create_fish: !request
method: POST
url: "{{host}}/fishes"
body: !json { "kind": "barracuda", "name": "Jimmy" }
authentication: !bearer "{{chains.token}}"
Recipe Body
There are a variety of ways to define the body of your request. Slumber supports structured bodies for a fixed set of known content types (see table below).
In addition, you can pass any Template to render any text or binary data. In this case, you'll probably want to explicitly set the Content-Type header to tell the server what kind of data you're sending. This may not be necessary though, depending on the server implementation.
Body Types
The following content types have first-class support. Slumber will automatically set the Content-Type header to the specified value, but you can override this simply by providing your own value for the header.
| Variant | Type | Content-Type | Description |
|---|---|---|---|
!json | Any | application/json | Structured JSON body; all strings are treated as templates |
!form_urlencoded | mapping[string, Template] | application/x-www-form-urlencoded | URL-encoded form data; see here for more |
!form_multipart | mapping[string, Template] | multipart/form-data | Binary form data; see here for more |
Examples
chains:
image:
source: !file
path: ./fish.png
requests:
text_body: !request
method: POST
url: "{{host}}/fishes/{{fish_id}}/name"
headers:
Content-Type: text/plain
body: Alfonso
binary_body: !request
method: POST
url: "{{host}}/fishes/{{fish_id}}/image"
headers:
Content-Type: image/jpg
body: "{{chains.fish_image}}"
json_body: !request
method: POST
url: "{{host}}/fishes/{{fish_id}}"
# Content-Type header will be set automatically based on the body type
body: !json { "name": "Alfonso" }
urlencoded_body: !request
method: POST
url: "{{host}}/fishes/{{fish_id}}"
# Content-Type header will be set automatically based on the body type
body: !form_urlencoded
name: Alfonso
multipart_body: !request
method: POST
url: "{{host}}/fishes/{{fish_id}}"
# Content-Type header will be set automatically based on the body type
body: !form_multipart
name: Alfonso
image: "{{chains.fish_image}}"
Chain
A chain is a intermediate data type to enable complex template values. Chains also provide additional customization, such as marking values as sensitive.
To use a chain in a template, reference it as {{chains.<id>}}.
Fields
| Field | Type | Description | Default |
|---|---|---|---|
source | ChainSource | Source of the chained value | Required |
sensitive | boolean | Should the value be hidden in the UI? | false |
selector | JSONPath | Selector to transform/narrow down results in a chained value. See Data Extraction via JSONPath | null |
selector_mode | SelectorMode | Control selector behavior when query returns multiple results | auto |
content_type | string | Force content type. Not required for request and file chains, as long as the Content-Type header/file extension matches the data. See here for a list of supported types. | |
trim | ChainOutputTrim | Trim whitespace from the rendered output | none |
See the ChainSource docs for detail on the different types of chainable values.
Chain Output Trim
This defines how leading/trailing whitespace should be trimmed from the resolved output of a chain.
| Variant | Description |
|---|---|
none | Do not modify the resolved string |
start | Trim from just the start of the string |
end | Trim from just the end of the string |
both | Trim from the start and end of the string |
Selector Mode
The selector mode controls how Slumber handles returns JSONPath query results from the selector field, relative to how many matches the query returned. The table below shows how each mode behaves for a query that produces no values ($.id) a single value ($[0].name) vs multiple values ($[*].name) for this example data:
[{ "name": "Apple" }, { "name": "Kiwi" }, { "name": "Mango" }]
| Variant | Description | $.id | $[0].name | $[*].name |
|---|---|---|---|---|
auto | If query returns a single value, use it. If it returns multiple, use a JSON array | Error | Apple | ["Apple", "Kiwi", "Mango"] |
single | If a query returns a single value, use it. Otherwise, error. | Error | Apple | Error |
array | Return results as an array, regardless of count. | [] | ["Apple"] | ["Apple", "Kiwi", "Mango"] |
The default selector mode is auto.
Examples
# Load chained value from a file
username:
source: !file
path: ./username.txt
---
# Prompt the user for a value whenever the request is made
password:
source: !prompt
message: Enter Password
sensitive: true
---
# Prompt the user to select a value from a static list
fruit:
source: !select
message: Select Fruit
options:
- apple
- banana
- guava
---
# Use a value from another response
# Assume the request recipe with ID `login` returns a body like `{"token": "foo"}`
auth_token:
source: !request
recipe: login
selector: $.token
---
# Use the output of an external command
username:
source: !command
command: [whoami]
trim: both # Shell commands often include an unwanted trailing newline
See Chain Source for more detailed examples of the various sources, and how they can be combined together.
Chain Source
A chain source defines how a Chain gets its value. It populates the source field of a chain. There are multiple source types, and the type is specified using YAML's tag syntax.
Examples
See the Chain docs for more complete examples.
!request
recipe: login
trigger: !expire 12h
---
!command
command: ["echo", "-n", "hello"]
---
!env
variable: USERNAME
---
!file
path: ./username.txt
---
!prompt
message: Enter Password
Variants
| Variant | Type | Description |
|---|---|---|
!request | ChainSource::Request | Body of the most recent response for a specific request recipe. |
!command | ChainSource::Command | Stdout of the executed command |
!env | ChainSource::Environment | Value of an envionrment variable, or empty string if undefined |
!file | ChainSource::File | Contents of the file |
!prompt | ChainSource::Prompt | Value entered by the user |
!select | ChainSource::Select | User selects a value from a list |
Request
Chain a value from the body of another response. This can reference either
| Field | Type | Description | Default |
|---|---|---|---|
recipe | string | Recipe to load value from | Required |
trigger | ChainRequestTrigger | When the upstream recipe should be executed, as opposed to loaded from memory | !never |
section | ChainRequestSection | The section (header or body) of the request from which to chain a value | Body |
Chain Request Trigger
This defines when a chained request should be triggered (i.e. when to execute a new request) versus when to use the most recent from history.
| Variant | Type | Description |
|---|---|---|
never | None | Never trigger. The most recent response in history for the upstream recipe will always be used; error out if there is none |
no_history | None | Trigger only if there is no response in history for the upstream recipe |
expire | Duration | Trigger if the most recent response for the upstream recipe is older than some duration, or there is none |
always | None | Always execute the upstream request |
Duration is specified as an integer followed by a unit (with no space). Supported units are:
s(seconds)m(minutes)h(hours)d(days)
Examples
!request
recipe: login
trigger: !never # This is the default, so the same as omitting
---
!request
recipe: login
trigger: !no_history
---
!request
recipe: login
trigger: !expire 12h
---
!request
recipe: login
trigger: !expire 30s
---
!request
recipe: login
trigger: !always
Chain Request Section
This defines which section of the response (headers or body) should be used to load the value from.
| Variant | Type | Description |
|---|---|---|
body | None | The body of the response |
header | Template | A specific header from the response. If the header appears multiple times in the response, only the first value will be used |
Examples
!request
recipe: login
section: !header Token # This will take the value of the 'Token' header
Command
Execute a command and use its stdout as the rendered value.
| Field | Type | Description | Default |
|---|---|---|---|
command | Template[] | Command to execute, in the format [program, ...arguments] | Required |
stdin | Template | Standard input which will be piped into the command | None |
username:
source: !command
command: [whoami]
Environment Variable
Load a value from an environment variable.
| Field | Type | Description | Default |
|---|---|---|---|
variable | Template | Variable to load | Required |
Examples
current_dir:
source: !env
variable: PWD
File
Read a file and use its contents as the rendered value.
| Field | Type | Description | Default |
|---|---|---|---|
path | Template | Path of the file to load (relative to current directory) | Required |
Examples
username:
source: !file
path: ./username.txt
Prompt
Prompt the user for text input to use as the rendered value.
| Field | Type | Description | Default |
|---|---|---|---|
message | Template | Descriptive prompt for the user | Chain ID |
default | Template | Value to pre-populated the prompt textbox. Note: Due to a library limitation, not supported on chains with sensitive: true in the CLI | null |
Examples
password:
source: !prompt
message: Enter Password
sensitive: true
Select
Prompt the user to select a defined value from a list.
| Field | Type | Description | Default |
|---|---|---|---|
message | Template | Descriptive prompt for the user | Chain ID |
options | SelectOptions | List of options to present to the user | Required |
Select Options
The list of options to present to the user. This can be a static list of values or a dynamic template to generate the list of options.
| Variant | Type | Description |
|---|---|---|
fixed | Template[] | Fixed list of options |
dynamic | Template | Template that renders to a JSON array |
Examples
fruit:
source: !select
message: Select Fruit
options:
- apple
- banana
- guava
fruit_response:
source: !request
recipe: list_fruit
# Assume this response body looks like:
# [{ "name": "apple" }, { "name": "guava" }, { "name": "pear" }]
selector: $[*].name
dynamic_fruit:
source: !select
message: Select Fruit
# This option is powerful when combined with the `selector` field on an
# upstream chain
options: "{{chains.fruit_response}}"
Content Type
Content type defines the various data formats that Slumber recognizes and can manipulate. Slumber is capable of displaying any text-based data format, but only specific formats support additional features such as querying and formatting.
Auto-detection
For chained requests, Slumber uses the HTTP Content-Type header to detect the content type. For chained files, it uses the file extension. For other chain sources, or Slumber is unable to detect the content type, you'll have to manually provide the content type via the chain content_type field.
Supported Content Types
| Content Type | HTTP Header | File Extension(s) |
|---|---|---|
| JSON | application/json | json |
Configuration
Configuration provides global settings for all of Slumber, as opposed to collection-level settings.
Location & Creation
By default, configuration is stored in a platform-specific configuration directory, according to dirs::config_dir.
| Platform | Path |
|---|---|
| Linux | $HOME/.config/slumber/config.yml |
| MacOS | $HOME/Library/Application Support/slumber/config.yml |
| Windows | C:\Users\<User>\AppData\Roaming\slumber\config.yml |
You can also find the config path by running:
slumber show paths config
You can open the config file in your preferred editor with:
slumber show config --edit
If the config directory doesn't exist yet, Slumber will create it automatically when starting the TUI for the first time.
Note: Prior to version 2.1.0, Slumber stored configuration in a different location on Linux (
~/.local/share/slumber/config.yml). If that file exists on your system, it will be used in place of the newer location. For more context, see issue #371.
You can change the location of the config file by setting the environment variable SLUMBER_CONFIG_PATH. For example:
SLUMBER_CONFIG_PATH=~/dotfiles/slumber.yml slumber
Fields
The following fields are available in config.yml:
commands.shell
Type: string[]
Default: [sh, -c] (Unix), [cmd, /S, /C] (Windows)
Shell used to execute commands within the TUI. Use [] for no shell (commands will be parsed and executed directly). More info
commands.default_query
Type: string or mapping[Mime, string] (see MIME Maps)
Default: ""
Default query command for all responses. More info
debug
Type: boolean
Default: false
Enable developer information in the TUI
editor
Type: string
Default: VISUAL/EDITOR env vars, or vim
Command to use when opening files for in-app editing. More info
follow_redirects
Type: boolean
Default: true
Enable/disable following redirects (3xx status codes) automatically. If enabled, the HTTP client follow redirects up to 10 times.
ignore_certificate_hosts
Type: string
Default: []
Hostnames whose TLS certificate errors will be ignored. More info
input_bindings
Type: mapping[Action, KeyCombination[]]
Default: {}
Override default input bindings. More info
large_body_size
Type: number
Default: 1000000 (1 MB)
Size over which request/response bodies are not formatted/highlighted, for performance (bytes)
persist
Type: boolean
Default: true
Enable/disable the storage of requests and responses in Slumber's local database. This is only used in the TUI. CLI requests are not persisted unless the --persist flag is passed, in which case they will always be persisted. See here for more.
preview_templates
Type: boolean
Default: true
Render template values in the TUI? If false, the raw template will be shown.
theme
Type: Theme
Default: {}
Visual customizations for the TUI. More info
pager
Alias: viewer (for historical compatibility)
Type: string or mapping[Mime, string] (see MIME Maps)
Default: less (Unix), more (Windows)
Command to use when opening files for viewing. More info
Ignored Fields
In addition to the above fields, any top-level field beginning with . will be ignored. This can be combined with YAML anchors to define reusable components in your config file.
Input Bindings
You can customize all input bindings in the configuration. An input binding is a mapping between an action (a high-level verb) and one or more key combinations.
For example if you want vim bindings (h/j/k/l instead of left/down/up/right):
# config.yaml
input_bindings:
up: [k]
down: [j]
left: [h]
right: [l]
scroll_left: [shift h]
scroll_right: [shift l]
select_recipe_list: [w] # Rebind from `l`
Each action maps to a list of key combinations, because you can map multiple combinations to a single action. Hitting any of these combinations will trigger the action. By defining a binding in the config, you will replace the default binding for that action. If you want to retain the default binding but add an additional, you will need to include the default in your list of custom bindings. For example, if you want vim bindings but also want to leave the existing arrow key controls in place:
input_bindings:
up: [up, k]
down: [down, j]
left: [left, h]
right: [right, l]
scroll_left: [shift left, shift h]
scroll_right: [shift right, shift l]
select_recipe_list: [w] # Rebind from `l`
Actions
| Action | Default Binding | Description |
|---|---|---|
left_click | None | |
right_click | None | |
scroll_up | None | |
scroll_down | None | |
scroll_left | shift left | |
scroll_right | shift right | |
quit | q | Exit current dialog, or the entire app |
force_quit | ctrl c | Exit the app, regardless |
previous_pane | shift tab | Select previous pane in the cycle |
next_pane | tab | |
up | up | |
down | down | |
left | left | |
right | right | |
page_up | pgup | |
page_down | pgdn | |
home | home | |
end | end | |
submit | enter | Send a request, submit a text box, etc. |
toggle | space | Toggle a checkbox on/off |
cancel | esc | Cancel current dialog or request |
delete | delete | Delete the selected object (e.g. a request) |
edit | e | Apply a temporary override to a recipe value |
reset | r | Reset temporary recipe override to its default |
view | v | Open the selected content (e.g. body) in your pager |
history | h | Open request history for a recipe |
search | / | Open/select search for current pane |
export | : | Enter command for exporting response data |
reload_collection | f5 | Force reload collection file |
fullscreen | f | Fullscreen current pane |
open_actions | x | Open actions menu |
open_help | ? | Open help dialog |
select_collection | f3 | Open collection select dialog |
select_profile_list | p | Open Profile List dialog |
select_recipe_list | l | Select Recipe List pane |
select_recipe | c | Select Recipe pane |
select_response | s | Select Request/Response pane |
select_request | r | Select Request/Response pane (backward compatibility) |
Note: mouse bindings are not configurable; mouse actions such as
left_clickcan be bound to a key combination, which cannot be unbound from the default mouse action.
Key Combinations
A key combination consists of zero or more modifiers, followed by a single key code. The modifiers and the code all each separated by a single space. Some examples:
wshift f2alt shift cctrl alt delete
Key Codes
All single-character keys (e.g. w, /, =, etc.) are not listed; the code is just the character.
escape/escenterleftrightupdownhomeendpageup/pguppagedown/pgdntabbacktab(equivalent toshift tab, supported for backward compatibility)backspacedelete/delinsert/inscapslock/capsscrolllocknumlockprintscreenpausebreak(sometimes just called Pause; not the same as the Pause media key)menukeypadbeginf1f2f3f4f5f6f7f8f9f10f11f12spaceplaypause(the media key, not Pause/Break)playpausereversestopfastforwardrewindtracknexttrackpreviousrecordlowervolumeraisevolumemute
Key Modifiers
shiftaltctrlsuperhypermeta
MIME Maps
Some configuration fields support a mapping of MIME types (AKA media types or content types). This allow you to set multiple values for the configuration field, and the correct value will be selected based on the MIME type of the relevant recipe/request/response.
The keys of this map are glob-formatted (i.e. wildcard) MIME types. For example, if you're configuring your pager and you want to use hexdump for all images, fx for JSON, and less for everything else:
pager:
image/*: hexdump
application/json: fx
"*/*": less
Note: Paths are matched top to bottom, so
*/*should always go last. Any pattern starting with*must be wrapped in quotes in order to be parsed as a string.
image/png: matchesimage/*image/jpeg: matchesimage/*application/json: matchesapplication/jsontext/csv: matches*/*
Aliases
In addition to accepting MIME patterns, there are also predefined aliases to make common matches more convenient:
| Alias | Maps To |
|---|---|
default | */* |
json | application/*json |
image | image/* |
Notes on Matching
- Matching is done top to bottom, and the first matching pattern will be used. For this reason, your
*/*pattern should always be last. - Matching is performed just against the essence string of the recipe/request/response's
Content-Typeheader, i.e. thetype/subtypeonly. In the examplemultipart/form-data; boundary=ABCDEFG, the semicolon and everything after it is not included in the match. - Matching is performed by the Rust glob crate. Despite being intended for matching file paths, it works well for MIME types too because they are also
/-delimited
Theme
Theming allows you to customize the appearance of the Slumber TUI. To start, open up your configuration file and add some theme settings:
theme:
primary_color: green
secondary_color: blue
Fields
| Field | Type | Description |
|---|---|---|
primary_color | Color | Color of most emphasized content |
primary_text_color | Color | Color of text on top of the primary color (generally white or black) |
secondary_color | Color | Color of secondary notable content |
success_color | Color | Color representing successful events |
error_color | Color | Color representing error messages |
Color Format
Colors can be specified as names (e.g. "yellow"), RGB codes (e.g. #ffff00) or ANSI color indexes. See the Ratatui docs for more details on color deserialization.
Neovim Integration
Slumber can be integrated into Neovim to allow you quickly switch between your codebase and Slumber.
Ensure you have which-key and toggleterm installed. Most premade distros (LunarVim, etc) will have these installed by default.
Add this snippet to your Neovim config:
local Slumber = {}
Slumber.toggle = function()
local Terminal = require("toggleterm.terminal").Terminal
local slumber = Terminal:new {
cmd = "slumber",
hidden = true,
direction = "float",
float_opts = {
border = "none",
width = 100000,
height = 100000,
},
on_open = function(_)
vim.cmd "startinsert!"
end,
on_close = function(_) end,
count = 99,
}
slumber:toggle()
end
local wk = require("which-key")
wk.add({
-- Map space V S to open slumber
{ "<leader>vs", Slumber.toggle, desc = "Open in Slumber"}
})
Logs
Each Slumber session logs information and events to a log file. This can often be helpful in debugging bugs and other issues with the app. All sessions of Slumber log to the same file. Currently there is no easy to way disambiguate between logs from parallel sessions :(
Finding the Log File
To find the path to the log file, hit the ? to open the help dialog. It will be listed under the General section. Alternatively, run the command slumber show paths log.
Once you have the path to a log file, you can watch the logs with tail -f <log file>, or get the entire log contents with cat <log file>.
Increasing Verbosity
In some scenarios, the default logging level is not verbose enough to debug issues. To increase the verbosity, set the RUST_LOG environment variable when starting Slumber:
RUST_LOG=slumber=<level> slumber ...
The slumber= filter applies this level only to Slumber's internal logging, instead of all libraries, to cut down on verbosity that will likely not be helpful. The available log levels are, in increasing verbosity:
errorwarninfodebugtrace
Lost Request History
If you've lost your request history, there are a few possible causes. In most cases request history is non-essential, but if you really want it back there may be a fix available.
If none of these fixes worked for you, and you still want your request history back, please open an issue and provide as much detail as possible.
Moved Collection File
If history is lost for an entire collection, the most likely cause is that you moved your collection file. To fix this, you can migrate your request history.
Changed Recipe ID
If you've lost request history for just a single recipe, you likely changed the recipe ID, which is the key associated with the recipe in your collection file (the parent folder(s) do not affect this). Unfortunately currently the only way to fix this is to revert to the old recipe ID.
Wrong Profile or Changed Profile ID
Each request+response in history is associated with a specific profile. If you're not seeing your expected request history, you may have a different profile selected than the one used to send the request(s).
Alternatively, you may have changed the ID of the associated profile. If so, unfortunately the only way to fix this is to revert to the old profile ID.
Shell Completions
Slumber provides tab completions for most shells. For the full list of supported shells, see the clap docs.
Note: Slumber uses clap's native shell completions, which are still experimental. This issue outlines the remaining work to be done.
To source your completions:
Bash
echo "source <(COMPLETE=bash slumber)" >> ~/.bashrc
Elvish
echo "eval (E:COMPLETE=elvish slumber | slurp)" >> ~/.elvish/rc.elv
Fish
echo "source (COMPLETE=fish slumber | psub)" >> ~/.config/fish/config.fish
Powershell
echo "COMPLETE=powershell slumber | Invoke-Expression" >> $PROFILE
Zsh
echo "source <(COMPLETE=zsh slumber)" >> ~/.zshrc
TLS Certificate Errors
If you're receiving certificate errors such as this one:
invalid peer certificate: UnknownIssuer
This is probably because the TLS certificate of the server you're hitting is expired, invalid, or self-signed. The best solution is to fix the error on the server, either by renewing the certificate or creating a signed one. In most cases this is the best solution. If not possible, you should just disable TLS on your server because it's not doing anything for you anyway.
If you can't or don't want to fix the certificate, and you need to keep TLS enabled for some reason, it's possible to configure Slumber to ignore TLS certificate errors on certain hosts.
WARNING: This is dangerous. You will be susceptible to MITM attacks on these hosts. Only do this if you control the server you're hitting, and are confident your network is not compromised.
- Open your Slumber configuration
- Add the field
ignore_certificate_hosts: ["<hostname>"]<hostname>is the domain or IP of the server you're requesting from